Computer Vision: Deep Learning Approach
Convolutional Neural Network (CNN)
A Convolutional Neural Network (CNN) comprises of one or more convolutional layers, pooling layers and one or more fully connected layers as in a standard multilayer neural network. The architecture of a CNN is designed to take advantage of the 2D structure of an input image. This is achieved with local connections and tied weights followed by some form of pooling which results in translation invariant features. Convolutional neural nets are at the heart of deep learning's recent breakthrough in computer vision. CNN use a few tricks to reduce the number of parameters that need to be learned, while retaining high expressiveness. These tricks include:
-
local connectivity: neurons are connected only to a subset of neurons in the previous layer,
-
weight sharing: weights are shared between a subset of neurons in the convolutional layer (these neurons form what's called a feature map),
-
pooling: static subsampling of inputs.

A CNN Architecture. (Image taken from Research Gate.)
Convolutional layers, a component of CNN architecture, take advantage of the stationary property of natural images which means the statistics of one part of the image are the same as any other part. This property suggests we can learn features from a part of the image and apply to other parts of the image. Features are learned over a small randomly sampled patch of the image and applied (convolved) over other patches of the larger image thereby obtaining a different feature activation values at each location in the image.
Convolutional layers, a component of CNN architecture, take advantage of the stationary property of natural images which means the statistics of one part of the image are the same as any other part. This property suggests we can learn features from a part of the image and apply to other parts of the image. Features are learned over a small randomly sampled patch of the image and applied (convolved) over other patches of the larger image thereby obtaining a different feature activation values at each location in the image.

A convolution operation. (Animation taken from the Stanford deep learning tutorial.)
CNN also utilize pooling for dimensionality reduction. Features obtained from the convolution layers can be fed into a SoftMax classifier but given the stationary property of natural images we can aggregate statistics of these features at various locations of the image. These summary statistics are much lower in dimension (compared to using all of the extracted features) and can also improve results (less over-fitting). The aggregation operation is known as pooling.
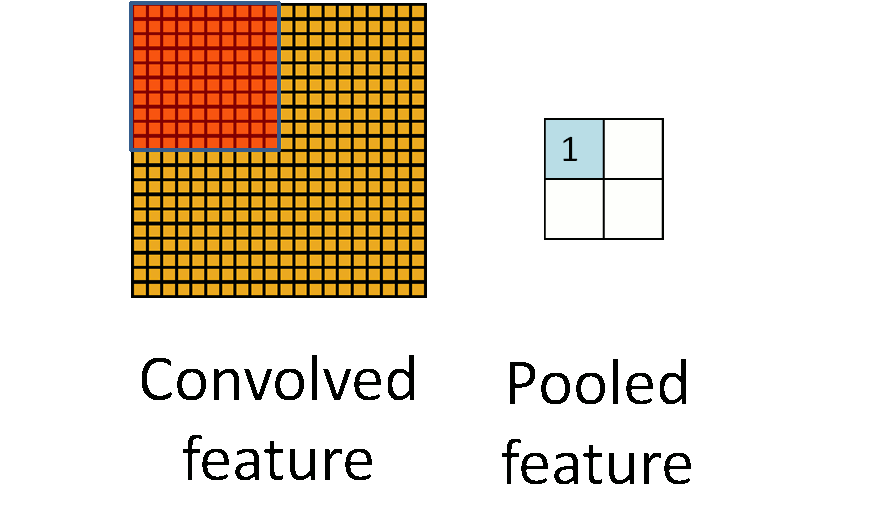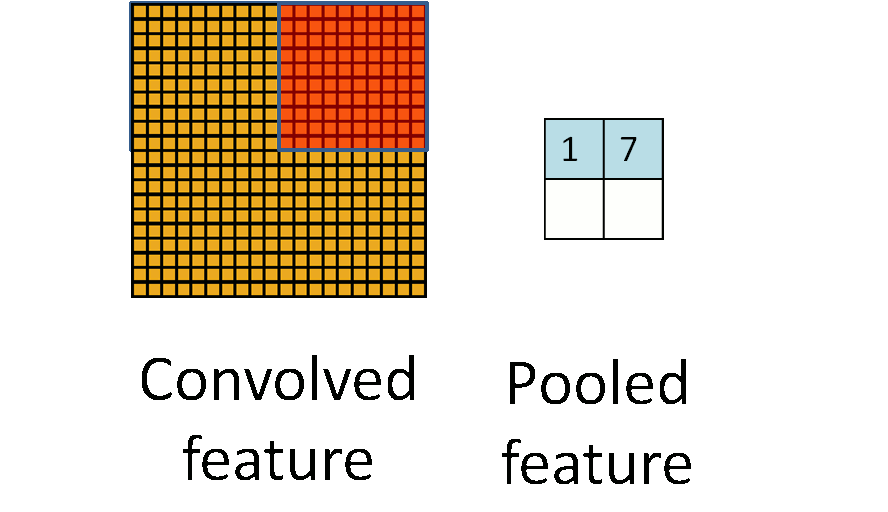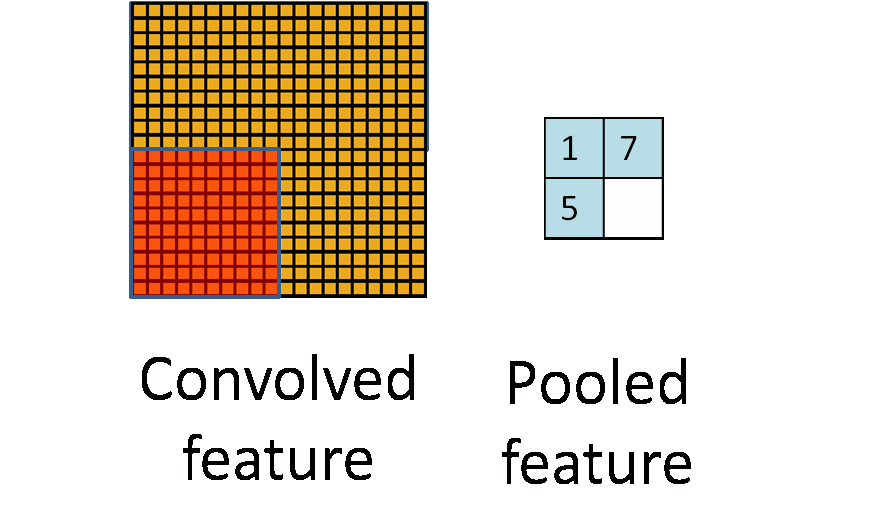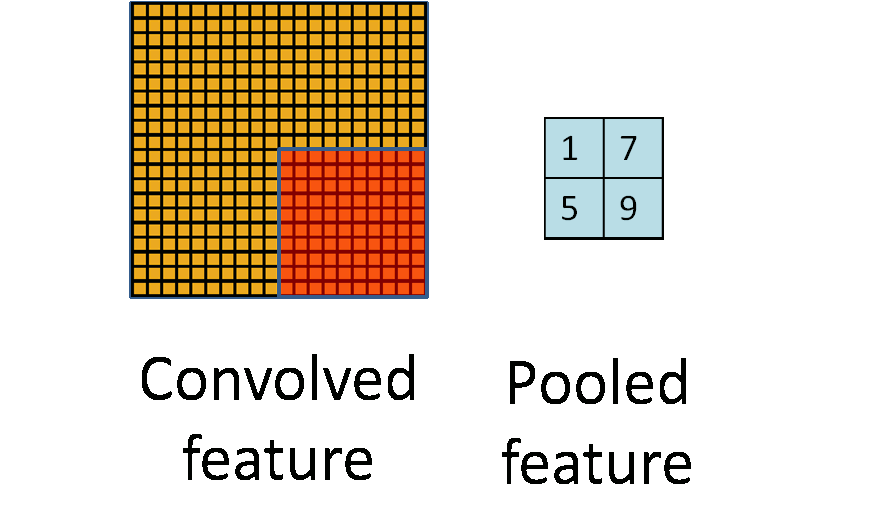
A pooling operation. (Animation taken from the Stanford deep learning tutorial.)
Data & Model
Data & Model
To train our weedeater model, we decided to generate our own images since there was no publicly available dataset we could use. Our data was generated by setting up an automated system to take pictures of the plants we planted. For our “weeds” we decided to use morning glories and marigolds since they are some common weeds a farmer might encounter. For our “plants” we decided to use peas and radishes. These plants were chosen because they have a quick germination time which allows us to get the images that are necessary for training our model. We also included pictures of dirt in our training set so that the sprayer knows when there are no plants on the field.

Our objective was to classify these images into the type of plant they are. We chose to use a convolutional neural network (CNN) for our image classification since this type of model is known to perform extremely well for image classification tasks. We took inspiration for the architecture from a Keras Blog Post by Franscois Chollet.
.png)
Since we can’t expect the user to take consistent images of plants all the time with the camera, we applied augmentations such as rotations, translations, shears, zooms, and horizontal reflections so that the model can generalize to various conditions.
Since we can’t expect the user to take consistent images of plants all the time with the camera, we applied augmentations such as rotations, translations, shears, zooms, and horizontal reflections so that the model can generalize to various conditions.
Results & Model Performance
Our model performed extremely well at classifying our plants achieving over 99% accuracy on the validation set.


On the test set, the model was extremely accurate, greater than 99% accuracy, and only made 11 errors as shown in the confusion matrix. There were misclassifications of peas as either marigolds or radishes. Since radishes and peas are our “desirable” plants this misclassification is expected to have low impact since both of those classifications are in the “plant” category which results in no herbicide sprayed. Confusing peas for marigolds, a weed, is a little more concerning since the model is choosing to not spray any herbicide on a weed but since spraying herbicides is not a one-time thing, there is a possibility that the herbicide can be applied on a second round of spraying.

We also examined how confident the model was in making these incorrect predictions. For about half of the misclassifications the model was not very confident (< 80%) in its predicted class.


Overall, our model was extremely effective at predicting the type of plant it sees, but we need to translate that predicted plant into a decision of whether or not to spray herbicide. For our use case, marigolds and morning glories should be sprayed with herbicide (“spray” class) and dirt, peas, and radishes should be left alone (“no spray” class). We decided to use a threshold of 90% predicted probability for the model to make a decision on whether to spray the herbicide. As shown by the confusion matrix above, this results in only 3 errors on the test set.
Our Github repository can be found here.